Wikipediaの記事データからコーパスを作成する方法(Windows版)
作るもの
Wikipediaの日本語記事データからコーパスを作ります。
具体的には、テキストファイルの中に、1行に1つの文を並べたものです。

コーパス作成の流れ
- Wikipediaの記事圧縮データをダウンロード
- 圧縮データの解凍
- テキストファイルに1行1文にまとめる
- (おまけ)形態素解析
1. Wikipediaの記事圧縮データをダウンロード
Wikipedia:データベースダウンロードにデータのライセンスや種類、形式等について書かれています。一通り目を通しておきましょう。
データのダウンロードは、ダウンロードページから行います。ここには直近にクロールされたデータが保管されています。
記事のデータは「jawiki-latest-pages-articles.xml.bz2」。クリックして保存します。
2. Wikipediaの記事圧縮データの解凍
WP2TXTをダウンロードし、インストールします。
(補足) 2015年7月1日現在、Windowsの.exeインストール・GUI版がダウンロードできるページが見つからないので、Windowsを使っている方用にzipファイル(5.2MB)を置いておきます。zipファイルを解凍し、WP2TXT-install-0.3.0.exeを実行してください(Windows7 32ビットのみ動作確認)。インストール先はどこでも結構です。そして、インストールしたフォルダの直下に、同梱のzlib1.dllを置いてください。
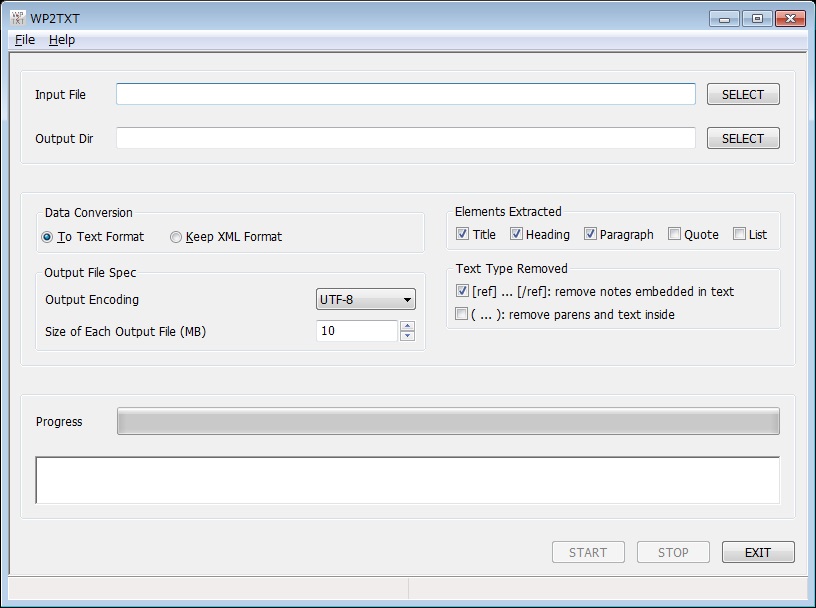
WP2TXT(Windows・GUI版)の使い方
- 「Input File」から先ほどWikipediaからダウンロードした圧縮ファイルを選択します。
- 「Output Dir」にデータの保存先を指定します。ファイルは分割して保存されるため、新しくフォルダを作っておくと分かりやすいです。
- 「Data Conversion」で「To Text Format」を選択します。(XMLが欲しいなら「Keep XML Format」を選択。)
- 「Elements Extracted」から抽出して欲しいデータを選択します。文章を集めたコーパスを作るなら、「Paragraph」のみでいいと思います。
- 「Output File Spec」の「Output Encodeing」は「UTF-8」を選択。「Size of Each Output File (MB)」はデフォルトの値でいいと思います。
- 「Text Type Remoced」で「[ref] ... [/ref]」にチェックを入れます。「( ... )」については、括弧とその中身が要らないという人はチェック。
- 「START」ボタンを押して、処理を開始します。処理には時間が掛かるので、気長に待ちましょう。
3. テキストファイルに1行1文にまとめる
1行1文にまとめる際に、文の切れ目となるのが句点(。)です。句点を目安に改行を入れていき、空行は削除する処理を行います。
1行1文にする手順
- WP2TXTで出力したファイルを一つずつ読み込む
- 1.で読み込んだファイルから1行ずつ取り出し、変数($line)に入れる。
- $lineが空、または$lineが句点(。)を含んでいない場合は、次の1行の処理(2.)に飛ぶ。
- ($lineの値に対しての処理) 句点(。)の後ろに改行を入れる。
- ($lineの値に対しての処理) 。(改行)」 となっている部分の改行を取り除く。(。(改行)」 → 。」)
- ($lineの値に対しての処理) 連続した改行を1つにする。
- $lineをファイルに出力する。
なお、この処理はかなり大雑把なものなので、正確でない可能性があります。
Perlによるプログラムの例
適当なフォルダの中に、以下のプログラム(line.pl)とWP2TXTで出力したファイルを入れてください。
コマンドプロンプトを開き、そのフォルダまで移動。
line.plを実行してください。sentencesというファイルが作成されます。
#----------------------------------
# line.pl
#----------------------------------
use strict;
use warnings;
use utf8;
use open IN => ":encoding(utf8)";
use open OUT => ":encoding(utf8)";
binmode STDIN => ":encoding(utf8)";
binmode STDOUT => ":encoding(utf8)";
binmode STDERR => ":encoding(utf8)";
use Encode 'encode';
main();
sub main {
#出力ファイル。ファイル名に.txtは付けない。(次のwhileで読み込んでしまうため。)
open my $out, ">", encode("utf8", "sentences") or die "Can't open sentences.txt : $!";
#フォルダ内のテキストファイルを1つずつ読み込む
while (<*.txt>) {
#どのファイルを処理しているかの確認
print "$_ started...\n";
#テキストファイルを開く
open my $in, "<", encode("utf8", "$_") or die "Can't open $_ : $!";
#テキストファイルから1行ずつ読み込む
while(my $line = readline $in){
#行末の改行コードを削除
chomp $line;
#読み込んだ行が空、または句点を含まない場合は、次の行の処理に飛ぶ
if (!$line || $line !~ /。/) {
next;
}
#句点の後ろに改行コードを挿入
$line =~ s/。/。\n/g;
#句点と鍵括弧の間の改行を削除
$line =~ s/。\n」/。」/sg;
#連続した改行コードの削除
$line =~ s/\n\n/\n/g;
#書き出し
print $out $line;
}
close($in);
}
close($out);
}
これでコーパスが作成できました。
4. (おまけ)形態素解析
形態素解析器にはMecabやChasen等があり、品詞や読み等を得ることができます。
ここではMecabを例に、先ほど作ったコーパスの形態素解析を行います。
Mecabのダウンロード
MeCab: Yet Another Part-of-Speech and Morphological Analyzerからダウンロードします。「ダウンロード」から「Binary package for MS-Windows」をダウンロードしてください。
ダウンロードした.exeファイルを実行し、Mecabをインストールします。インストールする際、文字コードはutf8を選択。インストールしたら、フォルダ内にbinフォルダがあるのを確認します。
形態素解析
Mecabのbinフォルダに、コーパス(先ほど作ったsentences)をコピーします。
コマンドプロンプトを開き、binフォルダに移動してください。そこで、「mecab.exe < sentences > results.txt」を実行します。時間がかかるので、処理が終わるまでしばらく待って下さい。
出力の例
アンパサンド 名詞,一般,*,*,*,*,* ( 名詞,サ変接続,*,*,*,*,* ampersand 名詞,一般,*,*,*,*,* , 名詞,サ変接続,*,*,*,*,* &) 名詞,サ変接続,*,*,*,*,* と 助詞,格助詞,引用,*,*,*,と,ト,ト は 助詞,係助詞,*,*,*,*,は,ハ,ワ 「 記号,括弧開,*,*,*,*,「,「,「 … 記号,一般,*,*,*,*,…,…,… と 助詞,格助詞,引用,*,*,*,と,ト,ト … 記号,一般,*,*,*,*,…,…,… 」 記号,括弧閉,*,*,*,*,」,」,」 を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ 意味 名詞,サ変接続,*,*,*,*,意味,イミ,イミ する 動詞,自立,*,*,サ変・スル,基本形,する,スル,スル 記号 名詞,一般,*,*,*,*,記号,キゴウ,キゴー で 助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ ある 助動詞,*,*,*,五段・ラ行アル,基本形,ある,アル,アル 。 記号,句点,*,*,*,*,。,。,。 EOS